如何在廣聯達鋼筋軟件中計算基礎構件XZD01的相關操作
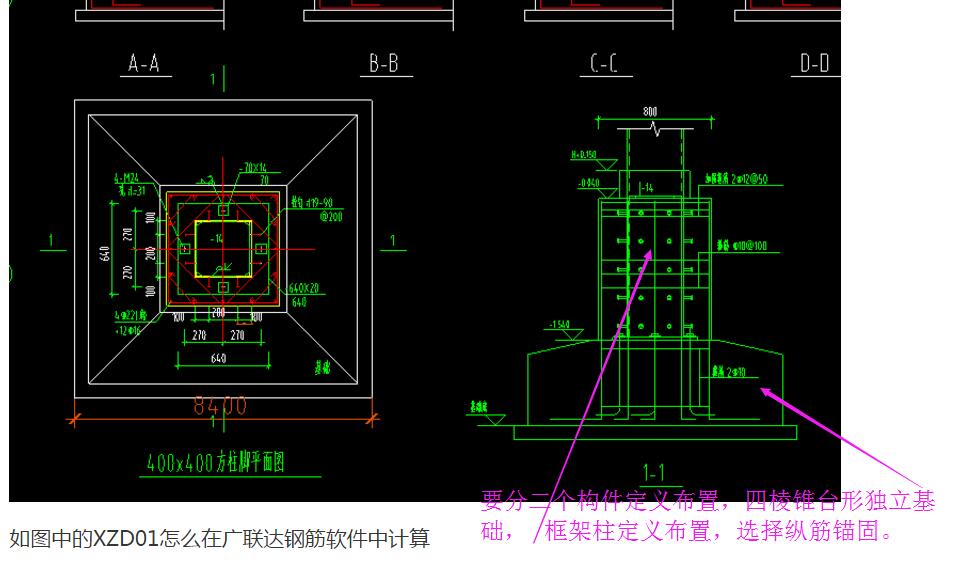
在廣聯達鋼筋算量軟件(如GTJ2021或GGJ)中,計算基礎構件的步驟需要結合具體參數。針對你提到的\
如若轉載,請注明出處:http://www.kh998.cn/product/1.html
更新時間:2026-06-19 02:27:55
在廣聯達鋼筋算量軟件(如GTJ2021或GGJ)中,計算基礎構件的步驟需要結合具體參數。針對你提到的\
如若轉載,請注明出處:http://www.kh998.cn/product/1.html
更新時間:2026-06-19 02:27:55